이번에는 Machine learning의 지도학습(Supervised Learning) 중 하나인 Linear Regression(선형회귀법) 중 하나인 Simple Linear Regression Analysis(단순선형회귀)에 대해서 알아보겠습니다.
간단하게 Linear Regression은 한개이상의 독립변수와 종속변수와의 선형 상관관계를 Modeling 하는 회귀기법입니다. 용어는 무지하게 어려워 보이지만... 사실은 간단하게 어느 공간에 점이 막 찍혀있고, 이 점들을 하나의 선으로 최대한 잘 표현하는 기법입니다.
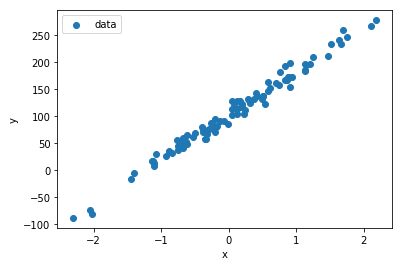
막(??) 이렇게 적당한 분포를 가진 점들이 찍혀있을때, 이것을 대표하는 선을 찾으면... 나중에 찍히는 점들이 대충 오차범위 내에서 어디에 찍힐지 예측을 하는 방법이라고도 할 수 있겠습니다. 머신러닝을 하는 이유도 현재 상황을 분석해서 나중에 입력을 예측하여 답을 주는 것이다... 일 수도 있으니까요.
용어를 2가지만 집고 넣어가면...
- x축의 입력변수를 보통 예측변수, 독립변수, 설명변수라고 하고,
- y축의 출력변수를 보통 Label, 종속변수라고 함
- 단순선형회귀는 독립변수가 1개일 경우인 선형회귀이고,
- 다중선형회귀는 독립변수가 2개 이상일 경우인 선형회귀 임
그럼 제목과 같이 이번에 알아볼 Simple Linear Regression Analysis(단순선형회귀)는 독립변수 1개, 종속변수 1개가 주어지는 환경에서 위의 그림처럼 2차원에 점이 찍혀질때, 이를 잘 표현할 수 있는 선을 찾고 이를 통해서 나중에 입력될 독립변수에 적당한 Label을 찍어주는 기법이라고 할 수 있겠습니다.
1. Basic
그럼 이 결과를 도출하기 위해 필요한 것들을 알아보겠습니다. 이 부분은 수학적으로 가능한데... 블로그에 어떻게 잘 표현해야할지 떠오르지 않아서 우선 수학적 증명은 최소화하고, 코드에 입력될 방식으로 간단하게 알아보겠습니다. 증명부분은 나중에 다른 글로 작성해 보겠습니다.
[Hypothesis(가설) 설정]
위와같이, 단순선형회귀는 2차원 내 분포된 점들을 하나의 선으로 표현한다고 했습니다. 이 중에서 직선으로 표현을 해본다고 가정하면... 학창시절 직선의 방정식을 떠올릴 수 있습니다.
y = ax + b
기억나시나요?? 여기서 x가 독립변수, y는 종속변수가 되는 것입니다. a는 기울기, b는 절편인데 머신러닝을 통해서 구해지는 부분은 a, b 입니다. 이를 ML(Machine Learning, 이하 ML통일) 용어로 하자면....
Hypothesis H = W * x + b (W는 weight 기울기, b는 bias 절편) 가 됩니다.
[Loss 오차]
가설을 세웠으면, 그 가설이 가장 정답에 근사하게 도출을 해야 합니다. 가설의 정확도는 오차를 통해서 높일 수 있는데, 이를 Cost Function 혹은 Loss Function이라고 합니다. 이름만 봐도 이것들을 낮춰야 좋을 것 같다는 느낌이 옵니다. 그렇다면 이 오차는 어떻게 구할까요??
실제 2차원 평면에 찍힌 점들의 종속변수 y가 있습니다. 그리고 ML을 통해서 나온 결과를 y^이라고 한다면, 오차는....
error = y^ - y (두개의 차)
일 것입니다. 이를 스마트하게 MSE, RMSE를 사용합니다.
- MSE (Mean Square Error) : y-y^를 제곱해서 평균내는 방식... 제곱?? 음수도 나오니 양수로 통일할래!!!
- RMSE (Root Mean Square Error) : MSE에서 Root를 더해서 구하는 방식... 왜?? 제곱하니 너무 숫자가 크네?? 그럼 난 부호만 양수로 할래!!!
간단하죠?? 이번에는 MSE를 사용할 것 입니다.
Loss = (1/n) * (y^ - y) ^ 2 입니다. 수학식 표현하기가 어렵네요...ㅠㅠ
(여기서 Loss = (1/2n) * (y^ - y) ^ 2 을 사용하기 합니다. 왜냐하면 미분할때 계산이 단순해지고 영향이 미비하기 때문입니다. 이유는 뒤에 나옵니다.)
[Optimizer]
Loss는 구했는데... 이러면 현재 상태만 알뿐 개선의 여지가 없습니다. 그렇다면 어떻게 가장 작은 오차를 가진 Model을 구할 수 있을까요?? 이는 Optimizer라고 불리는 최적화 알고리즘을 사용해야 합니다. 나중에 가면 들어보실 아이들이지만... 그 중에는 대표적으로 Gradient Descent, Adam 등이 있습니다.
그나마 해석이 가능한 GDA(경사하강법)을 본다면... 아래와 같이

W (weight)에 따라 어느지점보다 작아지면 Loss가 커지고, 반대로 어느지점보다 커지면 또 Loss가 커집니다. 따라서 Loss가 가장작은 지점은 2차함수의 가장 오목한 부분인데... 미분의 개념을 도입하면 해당 곡선의 기울기가 0인 지점입니다. 결국 미분값이 0은 지점을 계속 찾아나가는 방식입니다.
이게 모양이 계속 오목한 점을향해 계속 아래로 향한다고 해서 경사하강법이라고 합니다. 따라서 여기서 구해지는 기울기는 L(W)을 W에 대해서 미분합니다. chain rule을 적용해서 Loss에 대해서 미분하고 그 안에서 w에 대해서 미분하면 됩니다.
Gradient = (1/n) * (y^ - y) * x 이고,
GDA : W new = W old - LR(Learning Rate, 상수) * Gradient 가 됩니다.
2. with Numpy
이제 Simple Linear Regression Analysis(단순선형회귀)를 Numpy로 구현해 보겠습니다. 계속 진행할 과정에서 몇 안되는 Numpy를 통한 구현입니다.
- Dataset : scikit-learn에서 제공하는 dataset으로 총 100개를 추출하고 80개를 Training에 20개를 Test로 사용
사이킷런 (scikit-learn)은 Python을 위한 ML 라이브러리로 다양한 Dataset을 제공합니다.
https://scikit-learn.org/stable/
scikit-learn: machine learning in Python — scikit-learn 0.22.1 documentation
Model selection Comparing, validating and choosing parameters and models. Applications: Improved accuracy via parameter tuning Algorithms: grid search, cross validation, metrics, and more...
scikit-learn.org
사이킷런은 anaconda설치 시 자동으로 설치가 됩니다.
그럼 단계별로 진행하고 결과를 확인해 보겠습니다.
[Dataset 생성]
from sklearn.datasets import make_regression
X, y = make_regression(n_samples=100, n_features=1, bias=10.0, noise=10.0, random_state=2)
print(type(X))
print(type(y))
print(X.shape)
print(y.shape)
#############################
<class 'numpy.ndarray'>
<class 'numpy.ndarray'>
(100, 1)
(100,)모두 numpy의 ndarray형태로 생성되지만, 독립변수는 Matrix로 종속변수는 List로 추출됩니다.
(형태가 다름을 우선 주의해주세요!!)
그럼 간단하게 anaconda설치 시, 역시 자동으로 설치되는 matplotlib를 통해 scatter plot을 그려보겠습니다.
import matplotlib.pyplot as plt
plt.scatter(X, y, label="data")
plt.xlabel("x")
plt.ylabel("y")
plt.legend()
plt.show()
[Dataset 조작]
여기서 주의할 점은, Wx + b를 위해서 Matrix Multiply를 사용하려면... b를 W에 포함시키는 방법이 편합니다. 따라서 x에도 1의 값으로 열을 추가하고, W도 N by 2 Matrix로 생성해야 합니다.
X_bias = np.insert(X, 0, 1, axis=1)
print(X_bias.shape)
train_x = X_bias[:80]
test_x = X_bias[80:]
train_y = y[:80]
test_y = y[80:]
print(X_bias)
#################################
(100, 2)
[[ 1.00000000e+00 -8.78107893e-01]
[ 1.00000000e+00 1.35963386e+00]
첫 열을 1로 추가하고, shape를 확인해 보니... [100,2]로 열이 추가됨을 확인할 수 있습니다. 그리고 이전에 numpy때 배웠던 slice를 통해 80:20 으로 data를 나눕니다.
[Model 작성]
유의할 점은 2가지 입니다.
- train_y 가 make_regression을 통해 생성하면 list로 반환되기 때문에, Matrix로 expand_dims 를 해줘야 함
- gradiant 적용 시 train_x에 error를 곱하고 mean을 구하지만, 열이 2개이기 때문에 열기준으로 mean을 구하여야 합니다. 그래야 나중에 GDA할때 연산이 가능합니다.
class SLRA():
def __init__(self):
self.w = np.random.rand(2,1) * 0.001
def train(self, train_x, train_y):
self.epochs = 100
self.learning_rate = 0.1
loss_mem = []
#train_y 차원변환
train_y = np.expand_dims(train_y, axis=1)
for i in range(self.epochs):
hypothesis = np.matmul(train_x, self.w)
error = hypothesis - train_y
loss = np.mean(error * error) / 2
loss_mem.append(loss)
#공식적용 및 차원유지 그리고 T를 통한 형상유지
gradient = np.mean(error * train_x, axis=0, keepdims=True).T
#GDA적용
self.w -= self.learning_rate * gradient
return loss_mem
def test(self, target_x):
res = np.matmul(target_x, self.w)
return res
def pred(self, test_x, test_y):
test_y = np.expand_dims(test_y, axis=1)
cal = np.matmul(test_x, self.w)
error = cal - test_y
mse = np.mean(error * error)
rmse = np.sqrt(mse)
return rmse[Training 후 Loss 변화 관찰]
model = SLRA()
loss_mem = model.train(train_x, train_y)
x_epoch = list(range(len(loss_mem)))
plt.plot(x_epoch, loss_mem)
plt.title('Loss plot')
plt.xlabel('epochs')
plt.ylabel('Loss status')
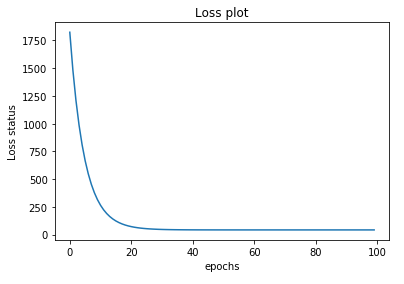
plt.show()아래 plot을 보면 Loss가 지속적으로 감소하다가 어느순간부터는 변화가 없음을 알 수 있습니다. 이는 정상적으로 ML을 완료했다는 판단 기준이 됩니다.
그렇다면, train_x를 가지고 최종 model에 적용해서 train_y를 구해서 학습전 data와 비교해 보겠습니다.
plt.scatter(train_x[:,1], train_y)
plt.plot(train_x[:,1], model.test(train_x), '-r')
plt.show()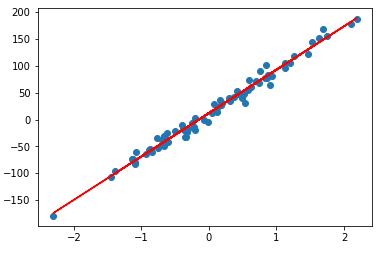
[Testing]
print(model.pred(test_x, test_y))
###################################
11.0424146294625RMSE의 경우도 11.04로 ML결과가 잘 나왔음을 확인할 수 있습니다.
3. with Tensorflow
너무너무나 길어져서.... 2편으로 넘겨야겠습니다...ㅠㅠ
-Ayotera Lab-
댓글